To begin, if you haven't already installed our "AI-Powered Chatbot" template, you need to do so in our Marketplace.
In order to enable the "AI-Powered Chatbot" to handle larger volumes of files, certain changes need to be made. Specifically, the OpenAI model used for embedding should be changed from text-embedding-ada-2 to text-embedding-3-large (to accommodate working with larger vectors), and the function responsible for writing data to the Chroma database needs to be modified.
Let's take the endpoint "/createVector" as an example. Initially, it will look like this:
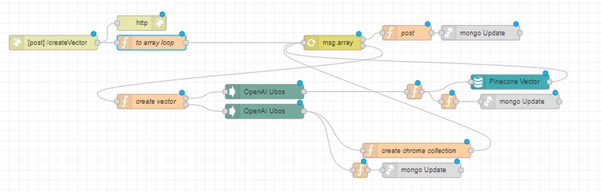
And here's how it will look after our modifications for working with large files:
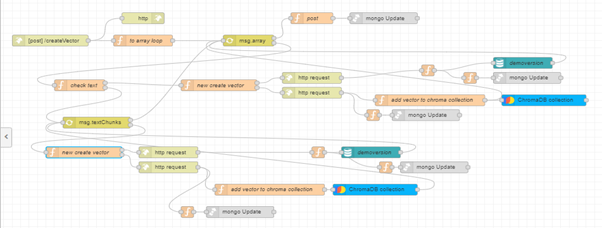
Before the "create vector" function node, we need to add another function to check the length of the received text from array-loop msg.array. The maximum number of tokens per embedding request is 8191.
(Here's where you can familiarize yourself with "Language model tokenization").
Therefore, we need to perform the following check:
- If each text is longer than, for example, 5500 characters, we split it into chunks of 5500 characters and push them into an array for passing into the next array-loop.
- If the text is shorter than the specified length, send it for vector creation.
This function, named "check text," will have the following code:
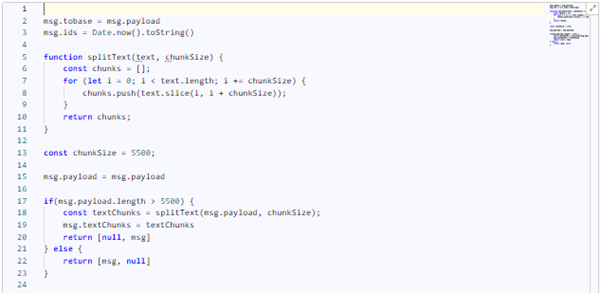
msg.tobase = msg.payload
msg.ids = Date.now().toString()
function splitText(text, chunkSize) {
const chunks = [];
for (let i = 0; i < text.length; i += chunkSize) {
chunks.push(text.slice(i, i + chunkSize));
}
return chunks;
}
const chunkSize = 5500;
msg.payload = msg.payload
if(msg.payload.length > 5500) {
const textChunks = splitText(msg.payload, chunkSize);
msg.textChunks = textChunks
return [null, msg]
} else {
return [msg, null]
}
The "splitText" function takes the text that needs to be divided into chunks and the required length of each chunk. The result will be an array of text chunks that we can pass into an array-loop further.
If the text either matches the specified length or we've split it into necessary chunks and passed them into an array-loop, we proceed to the function responsible for sending the embedding request ("new create vector").
In these functions, we specify headers with our OpenAI API_KEY, a settings object where we specify that we want to use the text-embedding-3-large model, pass the text for embedding, and check the type of the database. Thanks to these changes, we can work with vectors of greater length, namely 3072 instead of 1536 (Here's where you can familiarize yourself with “Embeddings”).
The code will look as follows:
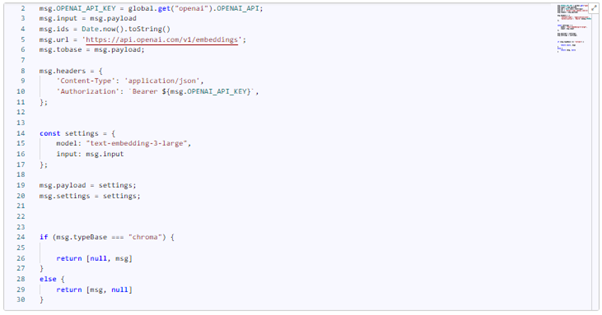
msg.OPENAI_API_KEY = global.get("openai").OPENAI_API;
msg.input = msg.payload
msg.ids = Date.now().toString()
msg.url = 'https://api.openai.com/v1/embeddings';
msg.tobase = msg.payload;
msg.headers = {
'Content-Type': 'application/json',
'Authorization': `Bearer ${msg.OPENAI_API_KEY}`,
};
const settings = {
model: "text-embedding-3-large",
input: msg.input
};
msg.payload = settings;
msg.settings = settings;
if (msg.typeBase === "chroma") {
return [null, msg]
}
else {
return [msg, null]
}
Next, replace the node "OpenAi Ubos" with "http request."
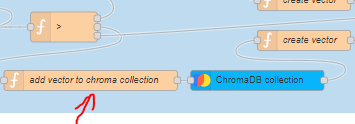
Additionally, we need to modify the following function used for writing the vector to the Chroma database and add the nodes "chroma collection" and select the "add" operation in it.
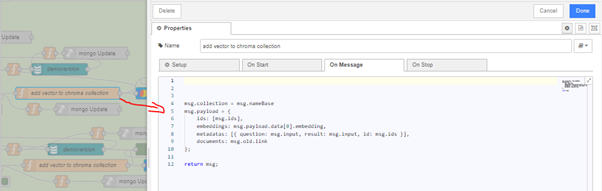
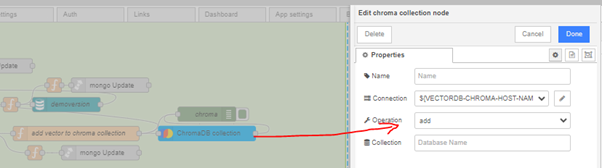
Now, following the same analogy, these actions need to be performed in other Endpoints where we send requests for embedding, write data to vector databases, or retrieve them (in which case the operation in "chroma collection" will be "query").
Here's an example of how the endpoint "/updateVector" looked and how it should look to handle larger volumes of information:


Also, to increase the amount of information you're passing to ChatGPT, you need to navigate to the "Bot" flow and increase the number of results returned from the Chroma database in the "add vector to chroma collection" function:
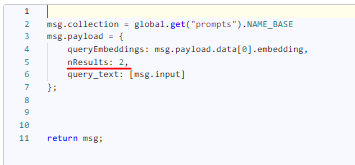
But keep in mind that your request to ChatGPT should not exceed the token limit for the chosen model, and also that the response from the models is limited to 4096 tokens (you can find a list and description of all ChatGPT models here).

Top comments (0)